Connect Data Lake with Vince


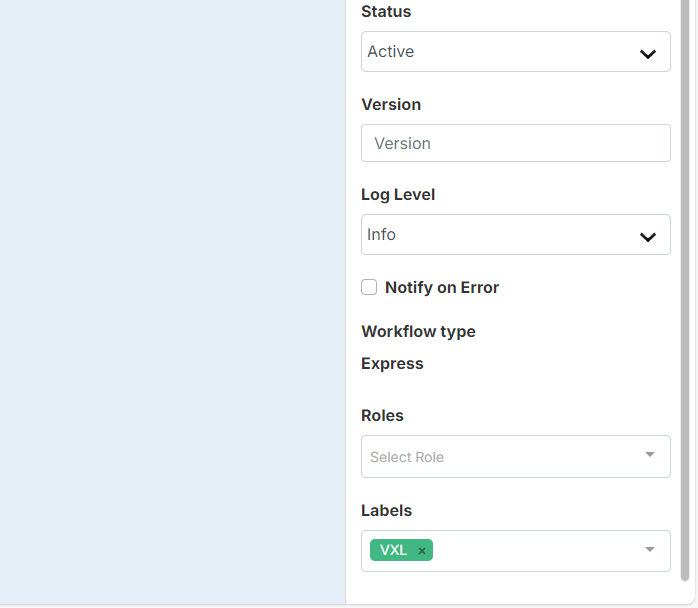
The VXL label
The Data Lake Step
Select the Data lake step in the workflow designer, as shown.
Activate component settings
There are 4 component settings needed to activate the data lake step
-
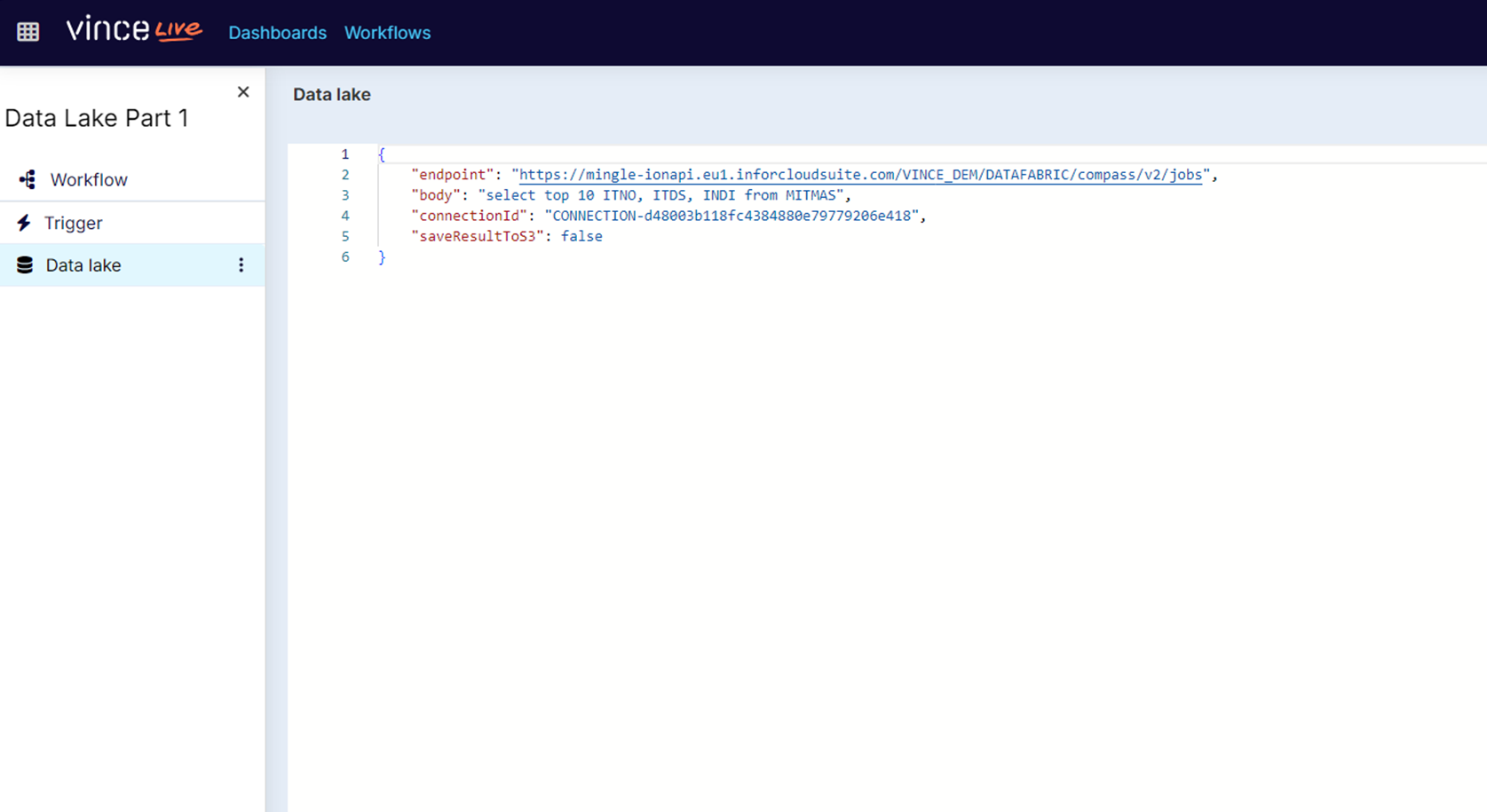
Endpoint – the data lake endpoint of the M3 environment to which this workflow will select data.
-
Body – the data lake sql statement
-
connectionId – A reference to the authentication credentials needed to call the endpoint
-
saveResultToS3 – instructions to save or not save the query result to an S3 “bucket” in AWS
We will detail these steps below.
Endpoint
Endpoint is the datafabric/compass endpoint of your M3 environment.
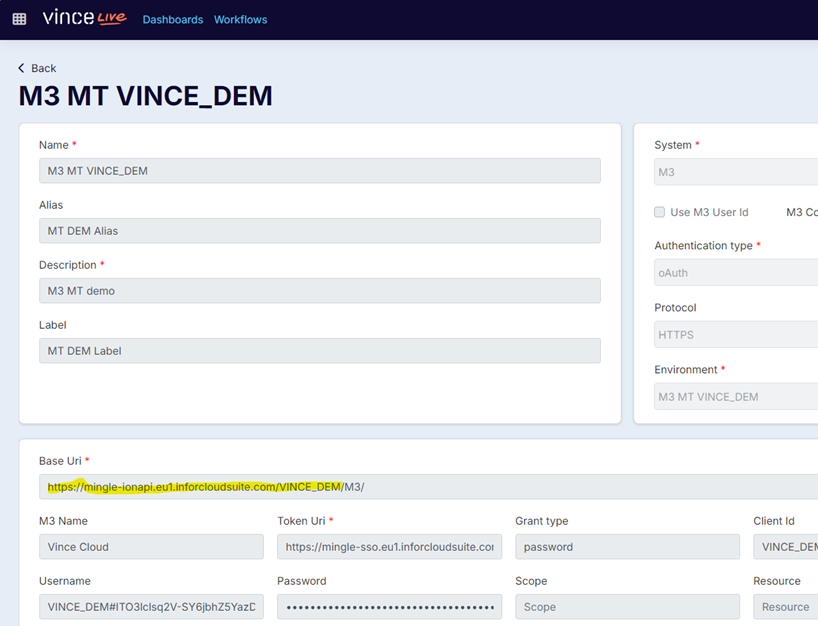
The host and environment will match your vince connection “Base Uri”, for example:
Note that the “/M3/” is not part of the Data Lake endpoint. Replace the “/M3/” with the following:
“/DATAFABRIC/compass/v2/jobs”.
For Example:
"endpoint": "https://mingle-ionapi.eu1.inforcloudsuite.com/VINCE_DEM/DATAFABRIC/compass/v2/jobs",
Body
Body is the Data Lake sql statement you wish to execute. It can be a hard-coded statement, or you can also use parameters, as described in the video series.
Example of a hard-coded statement:
"body": "select top 10 ITNO, ITDS, INDI from MITMAS"
Example of a parameterized statement that contains both hard-coded elements and parameters:

Note that if using parameters, you must define these parameters in a “transform” step that precedes the Data Lake step.
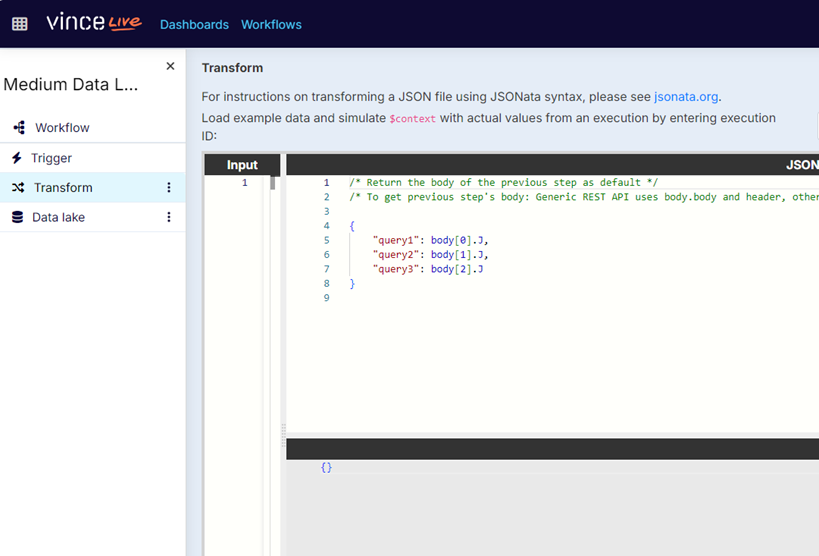
In this example, we define “query1”, “query2”, and “query3” as cells J1, J2, and J3 of the input spreadsheet:
For your convenience, here is the jsonata code:
"query1": body[0].J,
"query2": body[1].J,
"query3": body[2].J
}
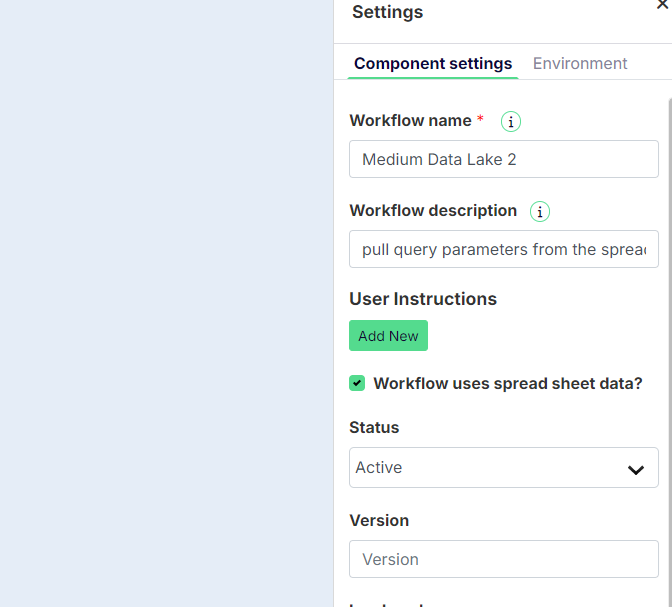
IMPORTANT: Note that if you use parameters, you must select the “Workflow uses spreadsheet data?” checkbox at the workflow level, as shown here.
ConnectionID
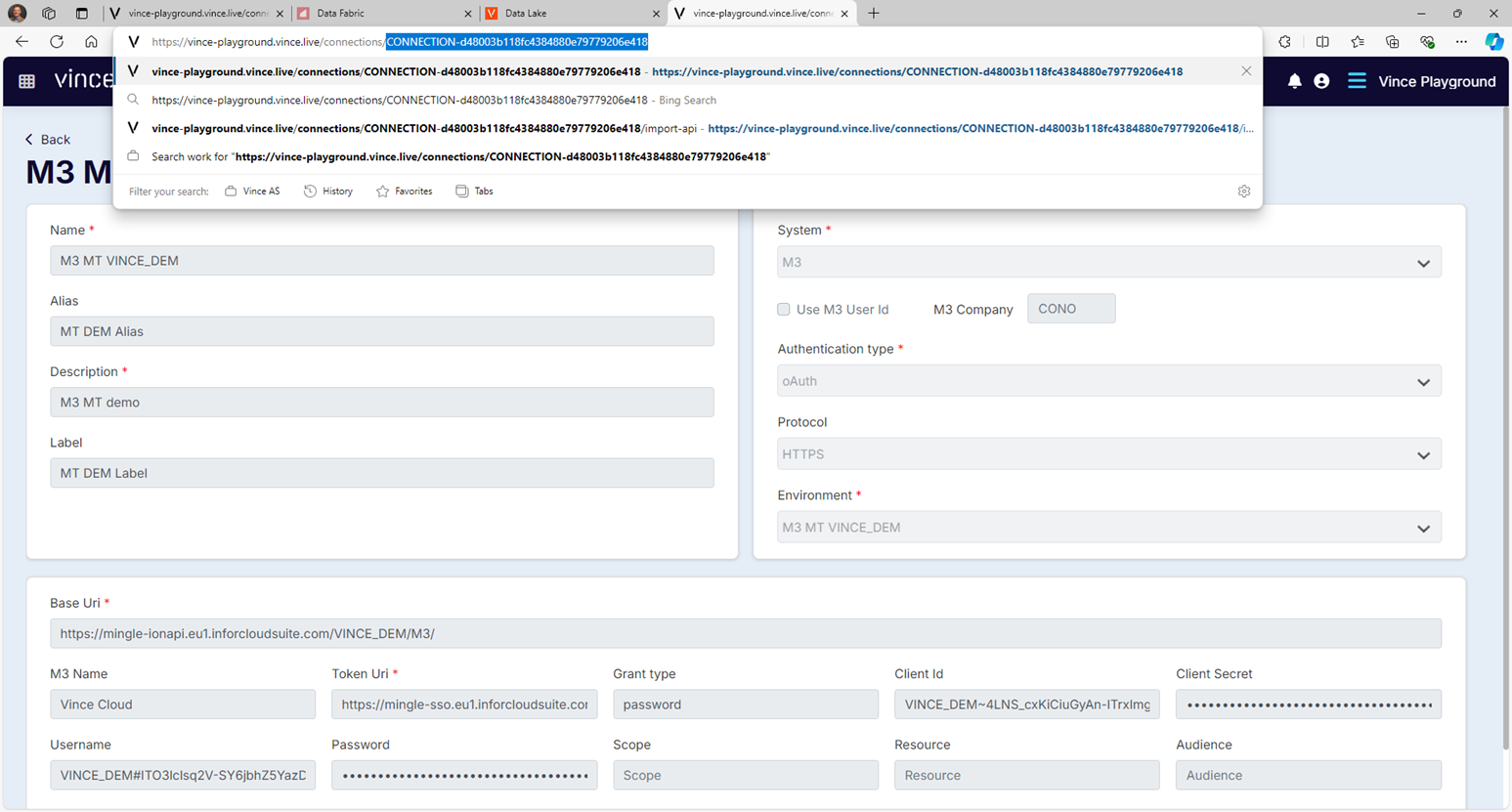
A reference to the authentication credentials needed to call the data lake endpoint. This will be found in the same connection management page as the Base Uri:
Copy and paste the GUID-like connection reference from the page containing the connection, and paste into the data lake connectionId item.
For example:
"connectionId": "CONNECTION-d48003b118fc4384880e79779206e418",
saveResultToS3
Always set to “false”
"saveResultToS3": false
Tenants do not have access to the S3 data storage locations so please set this to false.